Customer Segmentation Pipeline Prototype
Recommendation engines are a popular and widely-used application of machine learning. For example, Amazon, Netflix, and well, most online retailers use recommendation engines to cross-sell items. But what if you want to gain insight into customer purchasing patterns – interpetation, not just prediction?
Customer segmentation involves dividing customers into groups, with each group inhabiting some unique set of properties. Segmentation can be used for understanding the customer types and adjust business strategy to meet the needs of those distinct types.
In this case, I’m focusing on data involving explicit ratings (e.g., 1-5 stars) or implicit ratings (e.g., number of times a song was played or a page was viewed) – data representable as triplets of (user, item, rating). Regardless of scale, ratings represent the intensity of the users’ interests in the products. I used the MovieLens 100K data set since it’s similar to data like customer page views of web portals, even if the first involves explicit ratings and the second involves implicit ratings.
I’m interested in developing a segmentation pipeline in Spark, but I decided to start with a prototype in Python using scikit-learn.

Ingestion
- Data ingestion We generate a
n_customersxn_featuresmatrix from the initial data.
Unsupervised Learning
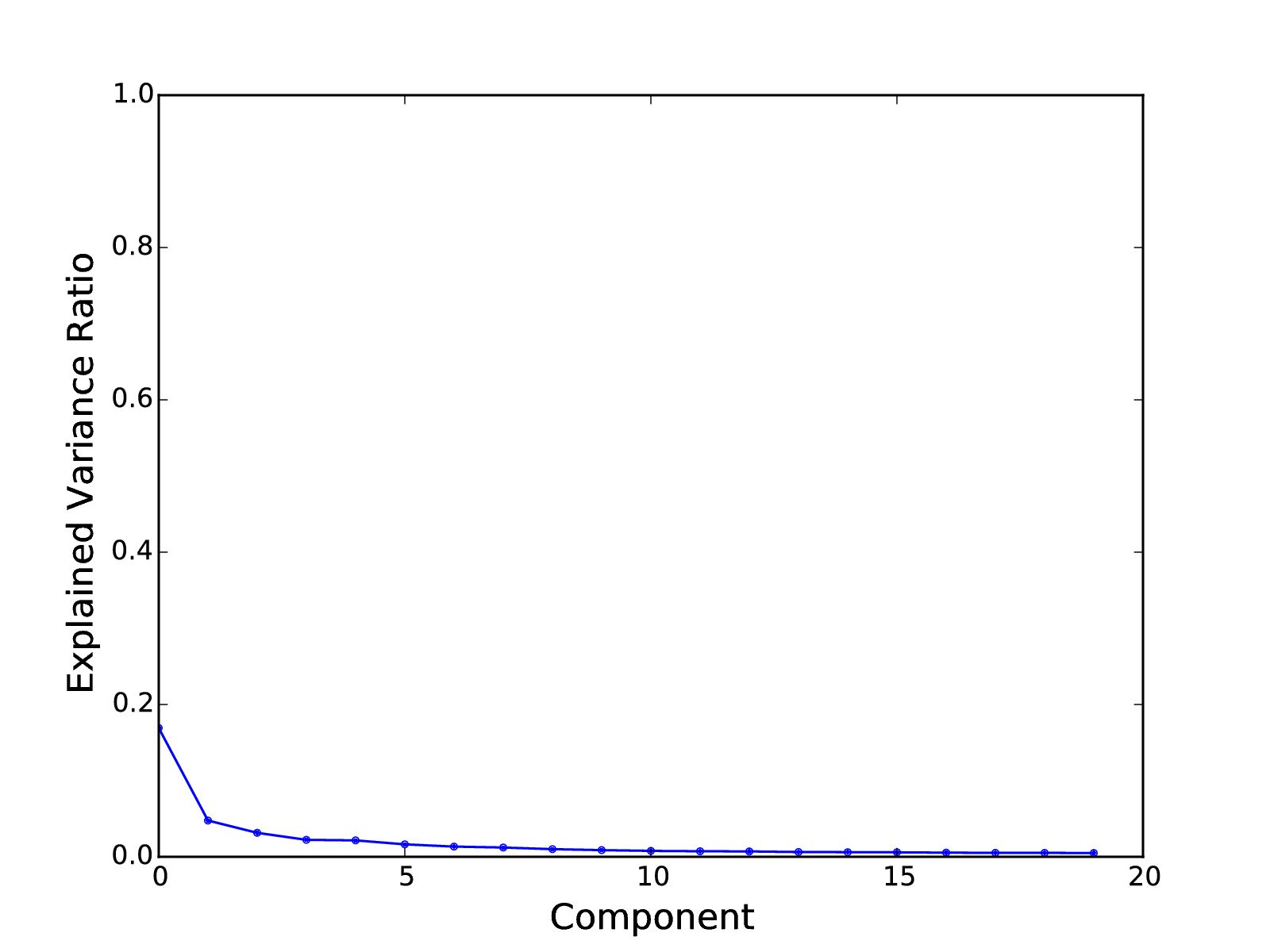
- PCA We perform a PCA of the matrix. We plot the explained variance ratios as a guide for choosing the number of PCs to use in projecting the full matrix to a reduced-dimensionality matrix. I chose to use 10 PCs.
- Clustering We cluster the projected data using K-Means. We plot the inertia for different numbers of clusters to aid use in choosing the number of clusters. (The term “inertia” is used by scikit-learn to represent the sum of the squared distances between each data point and its cluster center.) We use the clusters to label the customers. I chose to use 25 clusters.
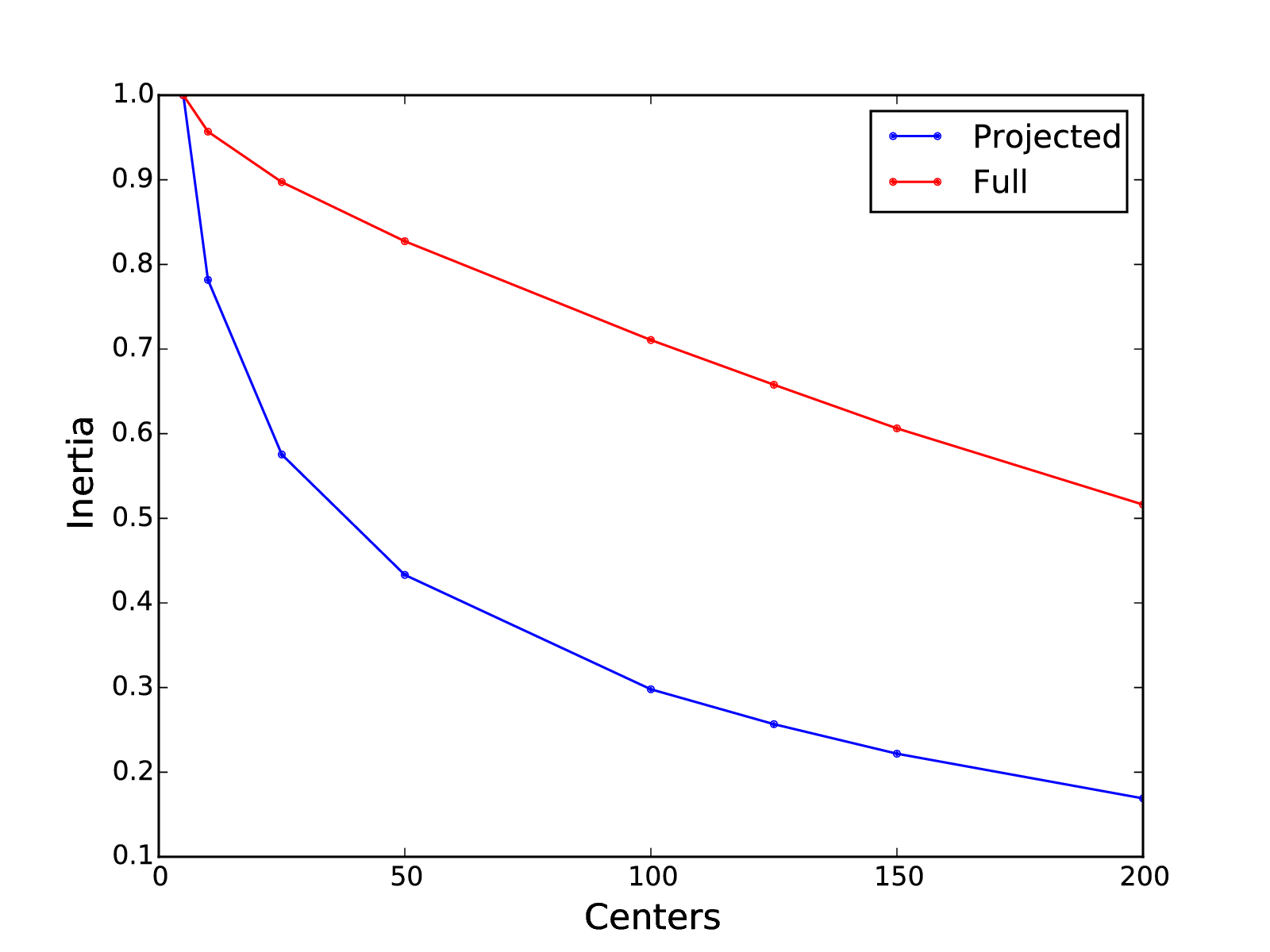
Note that I plotted the inertia of clusterings on the reduced-dimensionality and full data. Clustering on the PCA-projected reduced-dimensionality data results enables us to model the data with fewer clusters, each of which is better defined than on the raw data.
Validation
- Naive Bayes To validate the clusters, we train a Naive Bayes model on the full matrix with the cluster labels, predict the labels, and plot a confusion matrix of the cluster labels and Naive Bayes labels. If the matrix is mostly diagonal, then we can assume that the clusters are relatively distinct.

Analysis
-
TF-IDF Transformation To highlight the most unique elements of each cluster, we transform the movings ratings using Text Frequency-Inverse Document Frequency (TF-IDF). Ratings of movies with high ratings in nearly almost every cluster will be scaled down, while ratings of movies unique to a cluster will be not be affected.
-
Investigate Clusters At this point, we can evaluate our clusters. For each cluster, we can sort the movies by the average of the ratings by the cluster’s members.
Example Cluster Output
I picked two representative clusters from the output of the pipeline:
22 (33, 1682)
Star Trek: The Wrath of Khan (1982) 0.0694880144587
Raiders of the Lost Ark (1981) 0.0653438938566
Aliens (1986) 0.0644581524148
Terminator, The (1984) 0.0629864917916
Monty Python and the Holy Grail (1974) 0.0626759693905
Alien (1979) 0.0623002010617
Blade Runner (1982) 0.0619807716254
2001: A Space Odyssey (1968) 0.0602917668788
Empire Strikes Back, The (1980) 0.0601862501509
Princess Bride, The (1987) 0.0592987914342
24 (24, 1682)
Reservoir Dogs (1992) 0.0544705996296
Clerks (1994) 0.0541428493657
Professional, The (1994) 0.053078376281
Sling Blade (1996) 0.0490792536809
This Is Spinal Tap (1984) 0.048716171387
Blade Runner (1982) 0.047919452201
Bob Roberts (1992) 0.047538116705
Apocalypse Now (1979) 0.0468487388922
Clockwork Orange, A (1971) 0.0468088933486
Monty Python's Life of Brian (1979) 0.0466346420988
The two clusters are relatively distinct. The users in the first cluster generally prefer science fiction films, while the users in the second cluster prefer films that tend to be independent films with relatively unique and distinct profiles.
Conclusion
I’ve outlined a prototype for a customer segmentation pipeline, implemented with scikit-learn. I’ve described the basic steps as well as points for human evaluation and decision-making. I validated the pipeline using MovieLens data.
My next steps will be to implement the pipeline in Spark. Larger data sets and distributed computing represent a few challenges, mainly how to perform the dimensionality reduction.
If you want to play with the code, you can grab it here.