Evaluating Regularization and Optimization Algorithms for Logistic Regression on Spam Classification
Scikit-learn offers two implementations of Logistic Regression classification: LogisticRegression and SGDClassifier. The LogisticRegression class offers two regularization schemes (L1 and L2) and four optimizers: newton-cg, lbfgs, liblinear, and sag, while the SGDClassifier only uses a single optimizer (stochastic gradient descent) but offers an additional regularization option: elastic net. The SGDClassifier also has the benefit of supporting online learning – you can train the model on minibatches of data, which allows for training a model on a dataset too large to fit into memory.
Regularization Schemes
Generally speaking, regularization prevents overfitting of the model. How do we determine which regularization scheme to use?1 If the data has a group of correlated features, L2 regularization will keep (assign non-zero weights) to all of the features in the group but the weights of any single feature in the group will be lower. In constrast, with L1 regularization, only one feature in correlated group will be chosen (have a non-zero weight), producing a sparse model – L1 regularization effectively performs variable selection. L2 regularization can produce models with higher prediction accuracy, especially if data points are sparse and each data point will only contain a subset of the correlated features. L1 regularization can be useful in cases when model size is problematic (problems with many, many features) or when you want to perform variable selection.
Elastic net regularization incorporates both L1 and L2 regularization, offering benefits of both. Elastic net regularization also chooses subsets of the features but, in theory, tends to include or exclude entire groups of correlated features. Elasic Net regularization also performs better in situations where the number of features is much larger than the number of data points.
Choosing a Linear Regression Implementation
Once you’ve chosen a regularization scheme, you’ll need to choose a Linear Regression implementation and optimizer. If you want to use elastic net regularization, your only option is the SGDClassifier. Both the SGDClassifier and LinearRegression implementations support L1 and L2 regularization. For the LinearRegression implementation, the scikit-learn user guide suggests using the liblinear optimizer for L1 regularization and sag optimizer for L2 regularization.
Evaluation on Spam Classification
I wanted to find out how well the L1, L2, and elastic net regularization and the various optimizers work in practice. To evaluate the various options, I decided to train and evaluate Linear Regression models for spam classification on the publicly available trec07p dataset. In general, text classification problems tend to produce sparse features matrices since a small subset of words are very common while the rest occur infrequently.
I used Python’s built-in email.Parser implementation to extract the email bodies and BeautifulSoup to extract the text. I reserved the first 75% of the 75,419 emails for training and the remaining 25% for testing. I used scikit-learn’s TfidfVectorizer to parse the text and output features for a bag-of-words model. I set up the vectorizer to output binary features (whether or not a word is present) with no normalization or inverse document frequency (IDF) scaling. If a word appears in the test set but not in the training set, then it is ignored.
I evaluated five combinations of regularization schemes and optimizers:
- L1 regularization with the liblinear optimizer
- L2 regularization with the sag optimizer
- L1 regularization with sgd
- L2 regularization with sgd
- Elastic net regularization with sgd
Here are the resulting ROC curves:
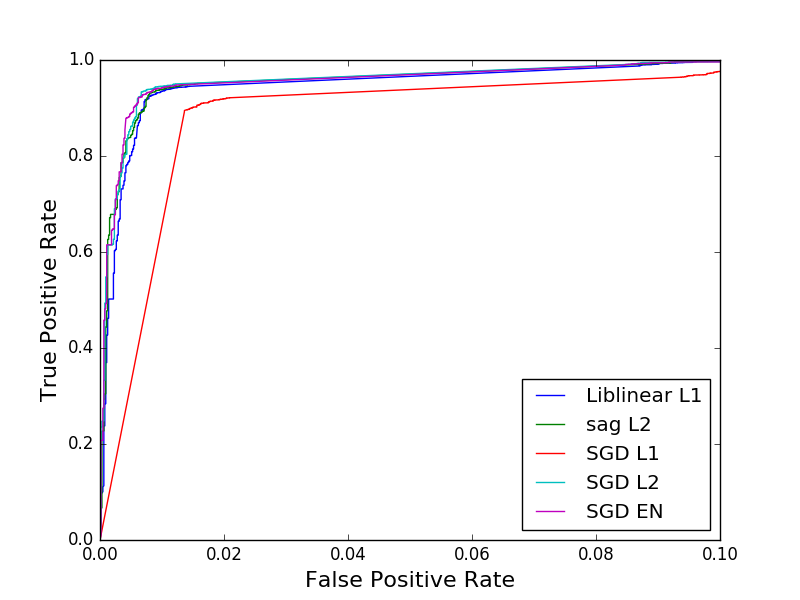
It’s interesting to note that most of the combinations offer similar accuracy with areas under the curve of 0.994-0.995 except for the L1/sgd model (red) which is a clear outlier with an AUC of 0.980.
What if we take sparsity into account?
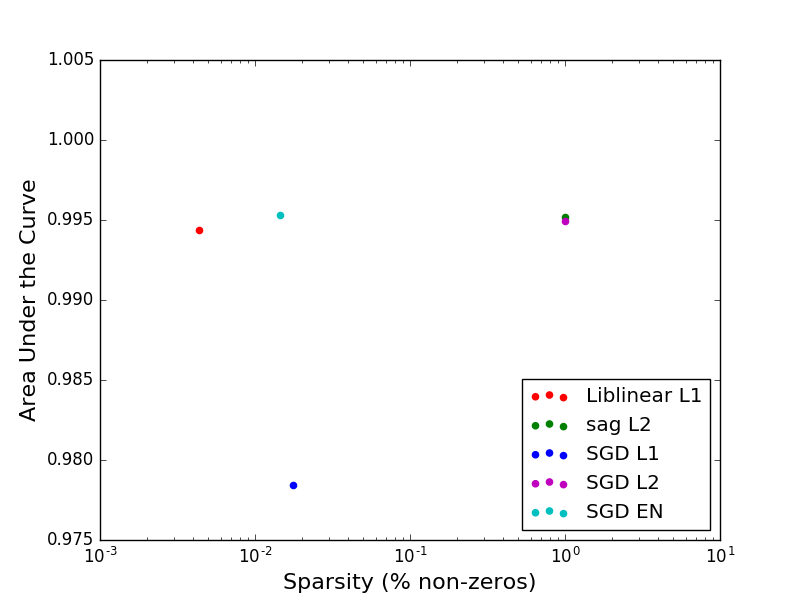
Neither model using L2 regularization are sparse – both use 100% of the features. We note that the models with L1 and elastic net regularization are much sparser. The L1/liblinear is the sparsest model, using only 0.4% of the features, while the L1/sgd model not only has the worst accuracy but is the least sparse of the sparse models with 2.3% of the features having non-zero weights. The elastic net model utilized 1.4% of the features, falling between the two L1 models with similar accuracy to the L1/liblinear model.
Conclusion
Our experiments provided some insight into how regularization affects the sparsity of models and which optimizers to choose for each regularization scheme. As expected, L1 and elastic regularization resulted in sparse models – using between 0.4% and 2.3% of the features. The L1/liblinear combination generated the sparsest model, while tying the L2 and elastic net models for accuracy. In fact, the sparsity seemed to have little effect on accuracy for this problem.
The L1/sgd model was an outlier in terms of accuracy, while also generating the least sparse model of the sparse models. If you wish to use L1 regularization for a Logistic Regression model implemented in scikit-learn, I would choose the liblinear optimizer over sgd. If you want to use sgd because of its support for online learning, I would choose elastic net regularization over L1 regularization – elastic net offers comparable accuracy to L2 regularization while generating a reasonably sparse model.
(You can download the script I used for these experiments and try it for yourself.)
1: Most of this comparison comes from Regularization and variable selection via the elastic net by Zhou and Hastie.