Categorical Variable Encoding and Feature Importance Bias with Random Forests
Random Forests are a popular and powerful ensemble classification method. One of RFs nice features is their ability to calculate the importance of features for separating classes. Among other applications, RFs’ feature importance scores have been used to identify SNPs associated with higher risk of diseases in genetic data.
Strobl, et al. and Altmann, et al. analyzed the variable importance calculated from RFs on categorical variables for bias. The researchers found that the variable importance of categorical variables was directly correlated with the number of categories – variables with more categories recieved higher variable importance scores.
Altmann, et al., tested for bias by generated synthetic data. The data had 31 categorical variables with 2 to 32 categories. For each sample, the value for each categorical variable and the label were sampled from the uniform distribution so that the variables were uncorrelated with the labels and equally uninformative.
I decided to recreate the experiment. I initially tried encoding the categorical variables using one-hot encoding. In this encoding, each category of each variable is modeled as a binary feature, and the features for a single variable are mutually exclusive so that only one can feature in the set can have a value of 1. For example, if my variable has four categories, I would create four binary features. I ended up with a feature matrix of 1000 samples and 527 features. I ran 100 simulations and plotted the distributions of the variable importances. (For each variable, I combined all of the feature importances into a single distribution.)
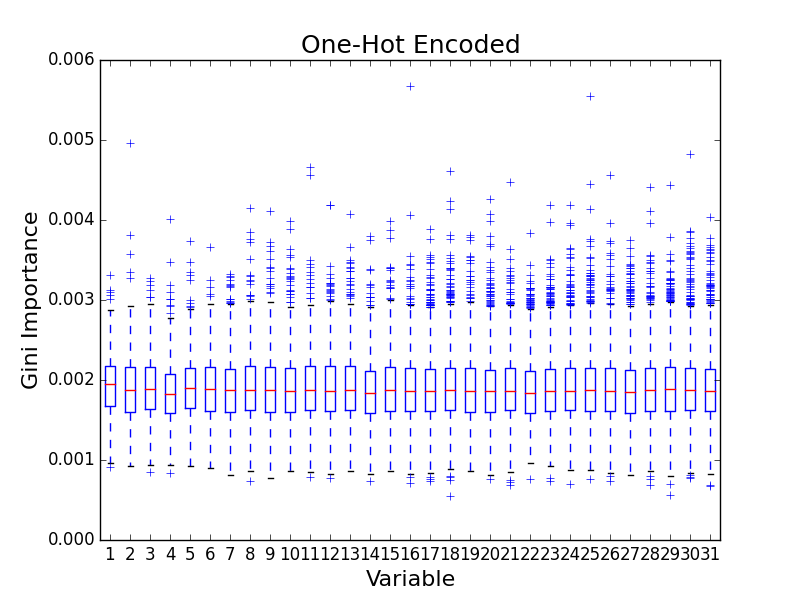
I was surprised to find no evidence of bias! It occurred to me that the authors probably didn’t use one-hot encoding. Rather, the authors probably encoded each categorical variable as a single feature, using an integer value to encode the category. For example, if a variable has four categories then valid features values would be 0, 1, 2, and 3. When I re-ran the simulations with the integer encoding, I saw the expected bias.
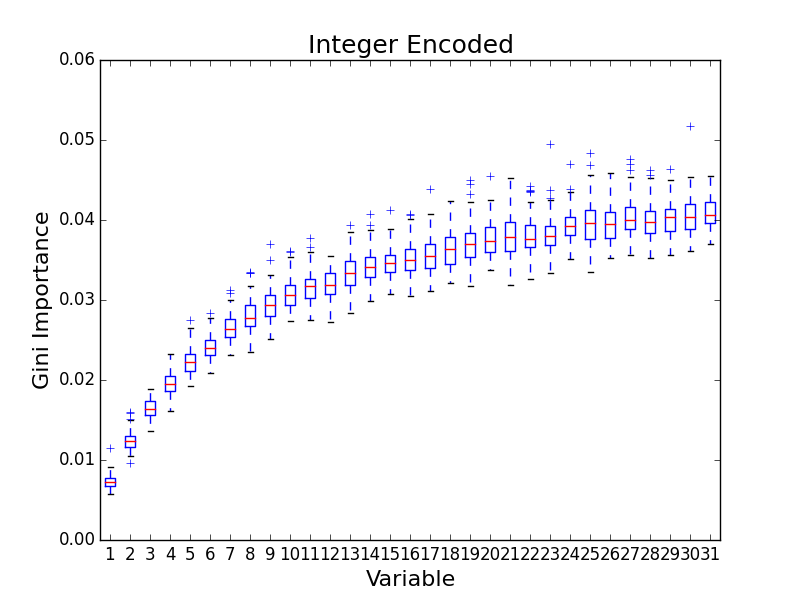
Feature engineering and encoding are incredibly important to training accurate maching learning models. Be careful.
(I posted my code so you can recreate my results.)