Spam Classification with a Fine-Tuned LLM, Part IV: Model Training and Inference
This post ends my series on fine-tuning a LLM for spam classification. In the previous posts, I described what I had learned about the 🤗 Dataset library, tokenization and loading pretrained models using the 🤗 transformers library. In this post, I describe how to perform training to fine tune a model, apply the model to perform classification, and (finally) evaluate how model performance scales with training set size.
The 🤗 transformers library uses two classes for training:
- TrainingArguments: a dataclass for storing training hyper-paraemters such as learning rates and the number of epochs.
- Trainer: a class for performing the actual training.
TrainingArguments Class
The TrainingArguments class takes a number of parameters familiar to people with deep learning frameworks:
- Learning rate and scheduling parameters: I found that a learning rate of $10^-5$ worked best for this problem.
- The choice of optimizer (AdamW optimizer by default)
- Number of training epochs: I found that 4 epochs was sufficient.
- Batch sizes: Because I didn’t pad the tokenized sequences, I had to limit batch sizes to 1. I might get better compute performance by padding the sequences and increasing the batch size. One challenge here is that the Llama 3.2 tokenizer doesn’t seem to have a padding token. The end of sentence token can be used to pad, but my understanding is that this cause output generation issues (not stopping generation when it should). It may not matter for this problem, so I should probably experiment with this.
- Weight decay: I just went with a value (0.01) I found in a tutorial.
A few parameters are more implementation specific:
fp16orbf16for training in half precision or bfloat-16, respectively. These parameters taken a boolean value, and only one can be set to true. Using either reduces memory usage in half versus single-precision floating point. The bf16 format is generally preferred. (In a previous post, I downloaded the model in bf16 precision because we anticipated that I would use the bf16 format.)save_strategy: How the model weights should be saved periodically during training. I used “no” (no saving) since training doesn’t take very long in my case.eval_strategy: How often to compute model prediction performance on an evaluation data set. To use this, a validation data set needs to be provided. I opted not to perform evaluation on a validation set and set this to “no”.logging_strategy: How often to output training statistics including the loss calculated on the training set. I set this to “epoch” so that output was generated every epoch.
training_args = TrainingArguments(
output_dir="rnowling/Llama-3.2-1B-spam",
learning_rate=1e-5,
# Fix: ValueError: Cannot handle batch sizes > 1 if no padding token is defined.
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
num_train_epochs=4,
weight_decay=0.01,
save_strategy="no",
logging_strategy="epoch",
load_best_model_at_end=True,
bf16=True,
)
Training Class
The Training class is simpler. Its constructor primarily takes a model name, TrainingArguments object, the tokenized training set, and a DataCollator instance. I didn’t need to provide a tokenized evaluation dataset since I didn’t enable evaluation on that in the training arguments.
The loss can be a hard metric to interpret. The compute_metrics
parameter allows passing a function to compute other metrics such as accuracy. I followed the example in the text classification example notebook,
but I was unable to get it to output the accuracy. I suspect that the metric is used for load_best_model_at_end by specifying the
metric_for_best_model parameter for the training arguments. It would be nice to figure out how to output accuracy and other metrics
in the training logs, though.
Execution of the training algorithm
is initiated by calling the train() method.
In the previous post, we loaded the weights for the meta-llama/Llama-3.2-1B model
and used it to initialize an instance of the AutoModelForSequenceClassification
class. In the following code snippets, the model variable references this object.
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_tokenized,
processing_class=tokenizer,
data_collator=data_collator
)
trainer_stats = trainer.train()
The logging output from training looks like so:
{'loss': 1.0216, 'grad_norm': 1.1015625, 'learning_rate': 7.5390625e-06, 'epoch': 1.0}
{'loss': 0.3898, 'grad_norm': 0.01251220703125, 'learning_rate': 5.0390625000000005e-06, 'epoch': 2.0}
{'loss': 0.1915, 'grad_norm': 0.00469970703125, 'learning_rate': 2.5390625000000003e-06, 'epoch': 3.0}
{'loss': 0.2087, 'grad_norm': 0.15234375, 'learning_rate': 3.90625e-08, 'epoch': 4.0}
{'train_runtime': 179.0466, 'train_samples_per_second': 2.86, 'train_steps_per_second': 1.43, 'train_loss': 0.4528963379561901, 'epoch': 4.0}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████| 256/256 [02:59<00:00, 1.43it/s]
Making Predictions
A trained model is good, but it’s better if we can use it to make predictions. :) The TextClassificationPipeline conveniently handles tokenization and inference.
pipeline = TextClassificationPipeline(model = model, tokenizer = tokenizer)
pred_results = pipeline(test_ds["text"])
The pipeline class implements the Python special method __call__ so that it can be called like a function. It take a string (to classify
a single piece of text) or a list of strings (to classify multiple strings). The result is a list of dictionaries, one per input and
in the same order as the input. (If a single string is passed, a list with a single dictionary is returned.) The dictionaries contain
the label name with the highest estimated probability and the associated probability:
[
{'label': 'spam',
'score': 0.9997175335884094},
...
]
I needed numerical labels to use the scikit-learn metrics, so I used the following snippet to create a list of numerical labels:
pred_labels = [label2id[result["label"]] for result in pred_results]
Scaling of Prediction Performance with Training-Set Size
Okay, now that I figured out how to fine tune a model for text classification, I can answer my second question: how does prediction performance scale with training set size? I performed fine tuning with a range of training set sizes. I used a test set size of 1024 samples. I ran 3 trials for each training set size, randomly selecting new training and testing sets from the original data set, and computed the mean and standard deviation of the prediction accuracy. For comparison, I performed the same experiment using the SGDClassifier logistic regression implementation in scikit-learn on features computed using the TfidfVectorizer with the default settings.
Here, I plotted the training set size versus the average accuracy for the two models (LLM - blue, logistic regression - orange). The error bars indicate the standard deviation.
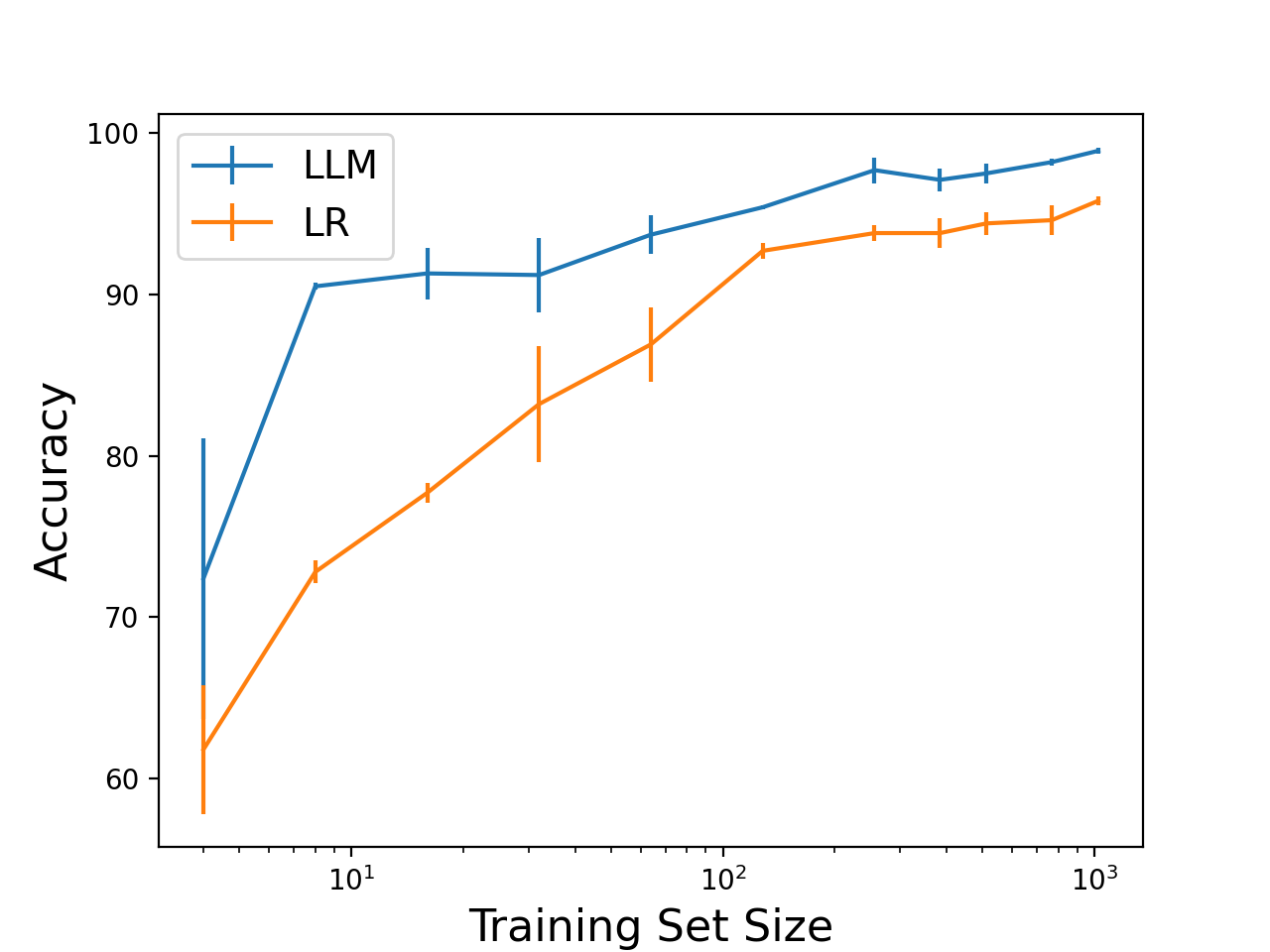
The accuracy of both methods improves as the training set size increases. The LLM performs better over the range of training set sizes evaluated and even sees a jump in accuracy with only 8 training samples. The performance of the LR model scales more slowly. What we see is the advantage of using a pretrained model: less training data are needed, significantly less in some cases.
The downside of the LLM is computation. Fine tuning a LLM requires a GPU to get reasonable training times, and even then, it is much slower than training the logistic regression model on a CPU. Further, the LLM requires more memory for storage and compute for inference. That said, I’m interested in investigating pruning to see how much smaller and faster I can make the LLM without impacting performance.
Conclusion
To review, we learned how to:
- Use the Hugging Face Dataset classes for custom data sets
- Tokenize text data
- Fine tune a LLM for sequence classification
- Perform inference with a trained model
and then evaluated how much data was needed to fine tune a LLM for text classification. Exciting!