Recommendation System Using K-Nearest Neighbors
In our previous blog post, we discussed using the hashing trick with Logistic Regression to create a recommendation system. In this blog post, we’ll demonstrate a simpler recommendation system based on k-Nearest Neighbors.
Like before, we’re going to focus on predicting whether or not a user will watch a movie; we are not focusing on estimating ratings. We’re evaluate the approach on the MovieLens 10M dataset. We binarized the ratings to create a user-movie interaction matrix where a 1 at row \(u\) and column \(m\) indicates that user \(u\) watched movie \(m\).
The nearest neighbors model computes the distance between every interaction vector in the query set against every interaction vector in the reference set. For each vector in the query set, the \(k\) closest reference vectors are returned. We evaluated two dissimilarity metrics, Euclidean distance and cosine dissimilarity. In our approach, we average the interaction vectors of the \(k\) neighbors to get an interaction score between 0 and 1 for each movie. The predicted interaction scores were then used to rank the movies.
We randomly chose 10,000 users without replacement for the reference set and an additional 1,000 users without replacement for the query set. For each query user, we randomly chose an equal number of movies they had and had not interacted with. Thus, each positive training or test example had a corresponding negative example (no class imbalance). For each movie, we used the interaction vectors’ entry as the true label. We then computed the area under the curve over all users, using the interaction vectors’ entries as the true labels and the rankings for the chosen movies based on the predicted interaction scores.
We plotted the AUCs for combinations of different values of \(k\) and Euclidean and Cosine dissimilarity metrics against the AUC obtained from the LR / hashing model:
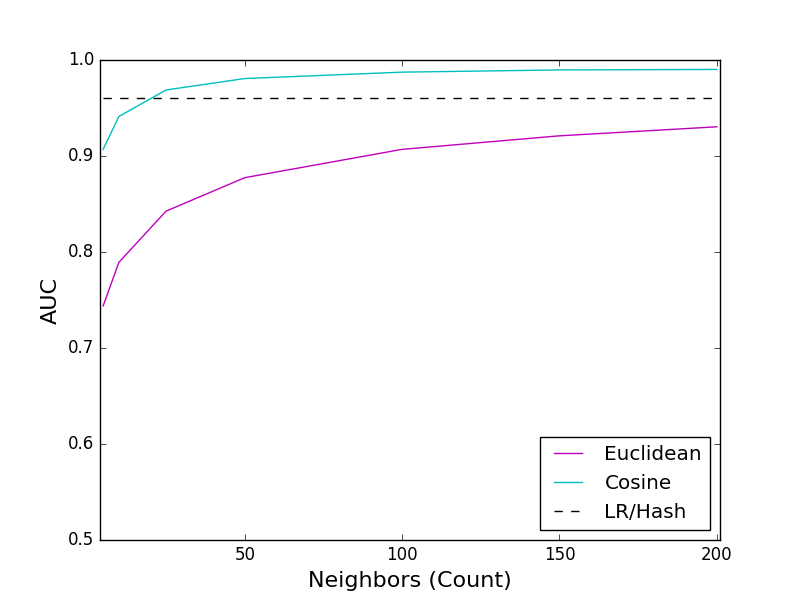
The solid magenta line gives the AUC for the KNN model using Euclidean distance. The solid cyan line gives the AUC for the KNN model using Cosine dissimilarity. The dashed black line gives the AUC for the LR / hashing model.
The Cosine KNN model achieved a maximum AUC of 99%, with 200 neighbors. In fact, the Cosine KNN model’s AUC surpassed that of the LR / hashing model with 25 neighbors, achieving an AUC of 97%. The Euclidean KNN achieved a maximum AUC of 93% with 200 neighbors, never achieving the accuracy of the LR / hashing model.
We released the implementation on GitHub under the Apache v2 License.
Conclusion
We presented a simple KNN model for user-based recommendations. We demonstrated the model with the 10M-ratings MovieLens dataset. Using the Cosine dissimilarity, the KNN model outperformed the LR / hashing model we previously demonstrated.